All eyes on eyes: Using FlexiConc to find patterns in concordances
Authors: RC21 team (Nathan Dykes, Stephanie Evert, Michaela Mahlberg, Alexander Piperski)
Published: 09 March 2026
Making sense of a large concordance is a challenging analytical task. For an analysis to be convincing, it must be methodologically rigorous and reproducible, which is not always easy to achieve with existing concordancing tools. To overcome this challenge, we have developed FlexiConc, a Python library that applies clearly defined algorithms to concordances, stores the history of operations in the form of a so-called analysis tree, and allows users to rearrange and subset concordance lines in order to produce interpretable concordance views.
To showcase the use of FlexiConc, we will analyze the word eyes in the British National Corpus (BNC). This word is one of the most important body part nouns, and its patterns of use have already drawn scholarly attention in 19th-century fiction (Mahlberg et al. 2020), but what about other genres and more recent texts?
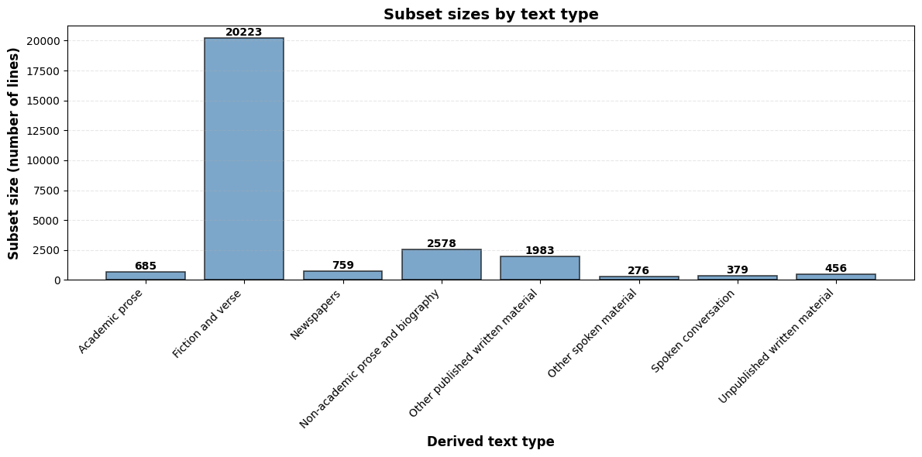
In the BNC, the word eyes occurs 27,339 times. Having loaded this concordance from BNCweb into FlexiConc, we perform the first analytical step by creating subsets by the metadata attribute “Derived text type”, which provides this information for every concordance line. The distribution of eyes across text types is very uneven: most of the examples (20,223, or 74%) occur in the Fiction and verse subset of the corpus, which is even more striking given that fiction only accounts for 18% of the BNC. However, even if we discard Fiction and verse, we are left with more than 7,000 examples.
Let us now focus on four subsets of published written English, other than Fiction and verse, namely Academic prose, Newspapers, Non-academic prose and biography, and Other published written material. The next step is to add annotation to the concordance, which will be useful for further analysis: we add sentence embeddings using the SBERT all-MiniLM-L6-v2 model to all concordance lines, thus supplying them with a numerical representation of their semantics. With these numerical representations, we can perform standard analytical operations used in data science, such as clustering: treating concordance lines as points in 384-dimensional space, we find clusters of points that are closer to each other, using the k-means algorithm (for a similar approach to reading concordances using word and sentence embeddings, see Anthony 2025). We produce 10 clusters for each subset in the hope that this will make a meaningful interpretation possible.
Here are two sample clusters from the Academic prose subset (denoted as Cluster 0 and Cluster 6; the numbers have no interpretive significance):
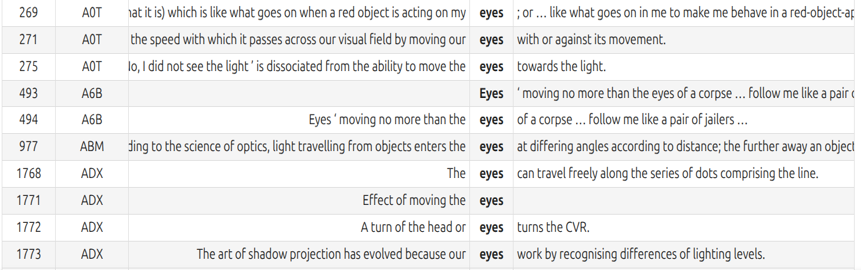

We can clearly see that Cluster 0 is focused on optical perception and physiology, while Cluster 6 mostly contains metaphorical uses of eyes in historical or ideological contexts.
However, even the clusters containing several dozen lines might be difficult to explore and interpret manually; for this reason, we need to label clusters in a meaningful way to assist interpretation. Using keywords as cluster labels has been proposed by Evert et al. (2016), and this approach is implemented in FlexiConc. For each cluster, we treat the tokens in the context window spanning five words to the left and five words to the right of the concordance node as a mini-corpus, and extract keywords from this corpus using the remaining nine clusters for the same text type as reference. The keyness measure we use is LRC (Evert 2022). Each cluster is labeled with up to ten most significant keywords. For instance, Cluster 0 shown in Figure 2 gets the label “field moving move left right objects front received movement along”, while Cluster 6 in Figure 3 is “king hero party soviet contemporary in modern was”.
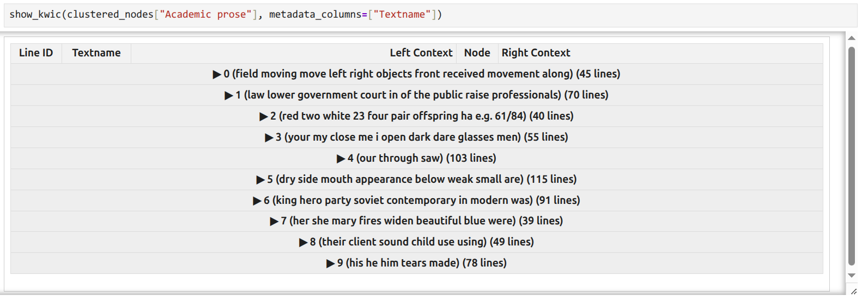

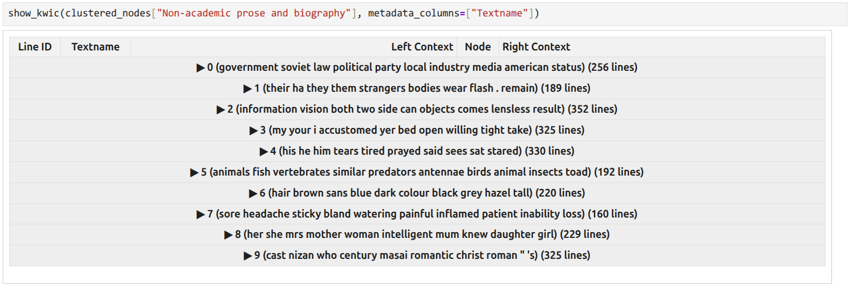
Exploring the keyword labels gives a first rough impression of the content of each cluster and makes it easier to spot relevant clusters. The analyst can then expand the cluster and see the concordance lines included in it to verify the interpretation of the keywords.
For instance, in the Newspaper subset we have three heavily gendered clusters focusing on females (Cluster 1 with 28 lines and Cluster 8 with 68 lines) and males (Cluster 2 with 129 lines), respectively. Cluster 1 often describes women’s emotional states:
| HER hands clasped and her | eyes | closed tightly, cancer victim Belinda |
| The old woman, despair in her | eyes | , broke down in tears, seeking solace |
In turn, Cluster 8 specifically focuses on eyes as an important element of the public image of females:
| Some observers said the Princess’s | eyes | seemed bloodshot |
Cluster 2, the male cluster, includes both types of contexts.
| he stops and stares and his | eyes | fill up with tears. |
| His good looking and twinkling | eyes | may have won him female fans |
A personal emotional perspective focused on the emotions of the speaker is offered by Cluster 4 (40 lines), domianted by the keyword my, but also by words such as tears and popping:
| I’m a tough, tough guy but I’ve been crying my | eyes | out all day |
| I remember my | eyes | popping out on stalks like a cartoon character |
Cluster 0, with its 54 lines, is centered on portrait-like contexts mentioning people’s faces and complexion, including eye colours (dark, brown):
| an arresting aristocratic beauty, with dark, dramatic | eyes | , fair hair and a patrician nose and chin |
In Cluster 3, with its 112 lines, eyes are the instrument that groups of people and crowds use to observe something. The keywords for this cluster include their, they, audience, use, while the singular possessive pronouns his and her are noticeably absent.
| it makes them appear ‘cool’ in the | eyes | of older children. |
Similarly, Cluster 6 (112 lines) offers a group-based but metaphorical use of eyes relating to national perspective or institutional viewpoint, with keywords such as England, government, church, French:
| East Germans tend to see it through the cruelly unblinking | eyes | of thoroughly Westernised consumers |
| British Rail has its | eyes | on the Bankside site |
Extremely focused attention, especially in social situations, is expressed by Cluster 7 (96 lines), where we often find the phrase all eyes are on X.
| All | eyes | are on Mr Brown, watching for his reaction |
This cluster is heterogeneous, because it also includes most examples where eyes functions as a verb (no part-of-speech restrictions were applied when querying the corpus):
| Dodson | eyes | $100m future |
In Cluster 5 (54 lines), with keywords bulging, between, fingers, bruises, black, swelling, attempted, and strangle, eyes are the locus of injury, damage, and disease:
| long-term damage to organs, including | eyes | and kidneys. |
| trussed in barbed wire, with their | eyes | gouged out |
Finally, one more perspective on eyes is offered by Cluster 9, which deals with consumer and health advice: vision tests, glasses, and eye care, at times shifting into an instructional mode.
| the price of safety is walking around with your | eyes | lowered and avoiding potentially dangerous situations |
This analysis shows that eyes can occur in many different contexts, which can be distinguished both by their semantics and by the words co-occurring with eyes.
We leave the comparison of these clusters to those identified in other text types to the interested reader—one can do this because FlexiConc allows for reproducible concordance reading. The concordance for eyes exported from BNCweb, as well as the Jupyter notebook used for this analysis and lists of keywords for all clusters, is available here. We welcome everyone to replicate our study and extend it.
References
- Anthony, Laurence. 2025. Concordancing with AI: Applications of word and sentence embeddings. Applied Corpus Linguistics 5(3). Article 100164. https://doi.org/10.1016/j.acorp.2025.100164
- Evert, Stefan, Paul Greiner, João Filipe Baigger & Bastian Lang. 2016. A distributional approach to open questions in market research. Computers in Industry 78. 16–28. https://doi.org/10.1016/j.compind.2015.10.008
- Evert, Stephanie. 2022. Measuring keyness. In Digital Humanities 2022: Conference Abstracts, 202–205. Tokyo / online.
- Mahlberg, Michaela, Viola Wiegand & Anthony Hennessey. 2020. Eye language – body part collocations and textual contexts in the nineteenth-century novel. In Ludwig Fesenmeier & Iva Novakova (eds.), Phraseology and Stylistics of Literary Language / Phraséologie et stylistique de la langue littéraire. Bern: Peter Lang, pp. 143–176.