
Concordance Reading × Association Measures
Methods to Organize a Dataset of German Support Verb Constructions
Author: Xinyao Lu, Friedrich-Alexander-Unviersität Erlangen-Nürnberg
Published: 11 June 2025
Introduction
How can we collect a dataset of German Support Verb Constructions (SVCs) from a reference corpus? Many approaches come to mind: iterating through lists of support verbs and verbal nouns, calculating association scores, or filtering collocations are all viable methods. However, upon closer examination, the task proves to be “easier said than done.” The verbal noun does not always exhibit a strong association with the support verb, and only a few SVCs appear in one collocation list containing thousands of entries. In this blog, I will discuss my considerations on the problem and propose a practical method that combines concordance reading and association measures to organize the dataset.
A Definition of SVCs
A Support Verb Construction (SVC), also known as a Stretched Verb Construction, is a type of verb phrase in which the core semantic meaning shifts from the verb to a noun while the verb itself functions primarily as a support verb . According to the English linguist D. J. Allerton, the verb in an SVC carries only a lightweight meaning. In contrast, the nominal or adjectival phrase conveys eventive meaning (i.e., the core action typically expressed by a verb)
For example:
- “Take a shower” means “to shower.”
- “Come to terms with someone” does not imply physical movement (“come”) but rather “to reach an agreement” (“term”) or “accept an uncomfortable situation.”
In German, typical SVCs include:
- “zum Ausdruck bringen” (to express)
- “in Kauf nehmen” (to accept)
- “in Rechnung stellen” (to charge)
Syntactic Analysis of German SVCs
German SVCs generally follow a uniform structure consisting of the following:
- A support verb (V)
- A prepositional phrase (PP) containing:
- A preposition (APPR)
- A verbal noun (NN)
- (Occasionally) a (mostly) definite article
Additionally, some SVCs include an adverbial complement, often in the form of a complementary prepositional phrase (PP-COM).
The following parse tree illustrates the syntactic structure of a German SVC according to the Tiger annotation scheme .
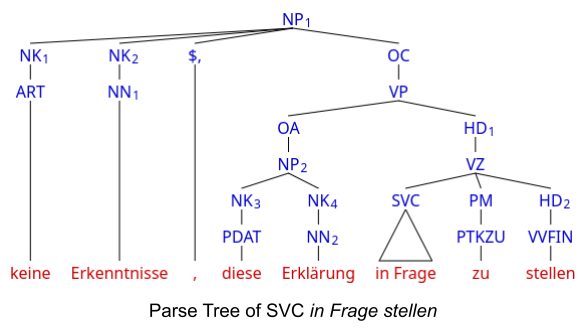
Three Criteria in Organizing Dataset
When compiling a dataset of SVCs from a corpus, three key criteria should be considered:
- Completeness – The dataset should omit as few SVCs as possible (minimizing false negatives).
- Accuracy – The dataset should exclude non-SVC entries (minimizing false positives).
- Efficiency – The workload should be affordable.
For this study, I used the Tageszeitung Corpus (1986–2011), containing 455 million tokens of German newspaper texts. I accessed it via FAU Erlangen-Nürnberg’s CQPweb server.
The process involves two main steps:
- Exhaustive search and documentation (prioritizing completeness).
- Extraction of documented SVCs from the corpus (prioritizing accuracy).
A major difficulty is the lack of a decisive indicator for SVCs: only a small subset of verbal nouns appear as frequent collocations or exhibit strong associations with support verbs.
The Role of Association Measures
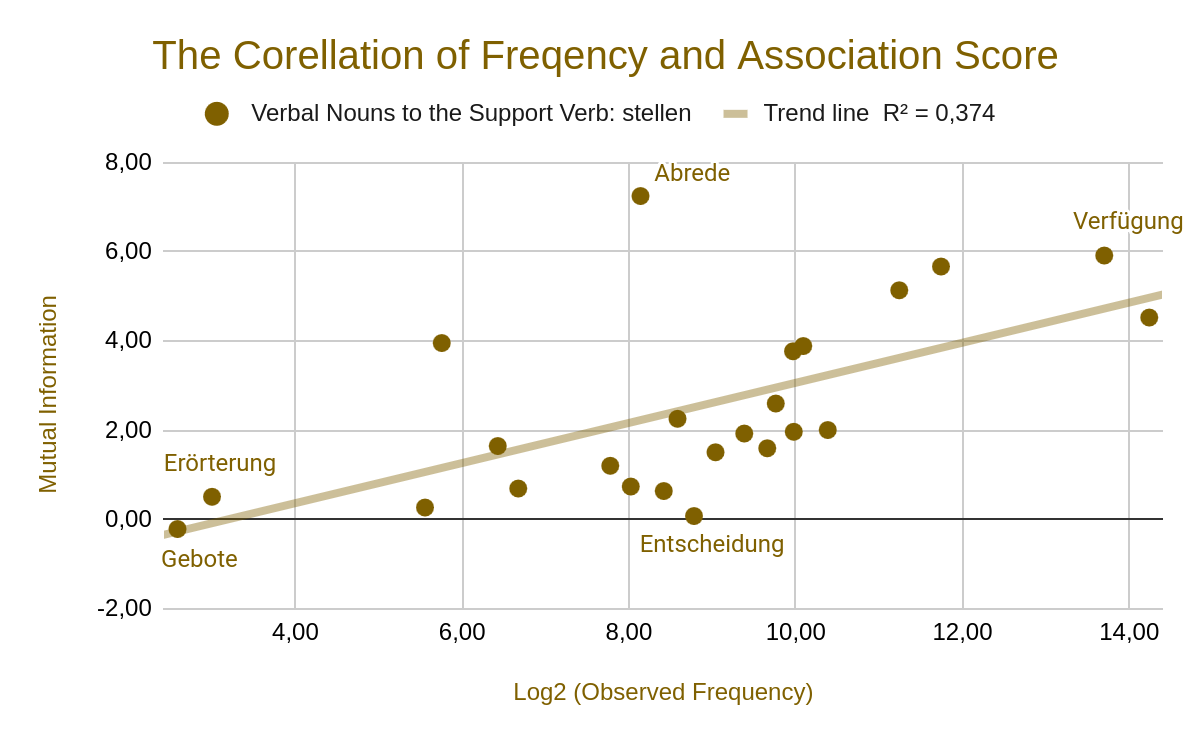
A case study examining collocations of the German verb stellen revealed that:
- Nearly all SVCs show a positive association between verbal nouns and support verbs.
- Essentially, association scores are linearly correlated with SVC frequency.
These findings suggest that association measures remain a meaningful indicator, helping narrow down the range of collocations requiring manual review. Additionally, lexicographical resources or AI tools can filter out proper nouns, further refining the list. In the stellen case study, manual judgment was ultimately required for fewer than 100 entries.
The Role of Concordance Reading
After documenting the SVCs, we need to find the appropriate query syntax to ensure accuracy. A naive query matching all co-occurrences of a verbal noun and the support verb often includes other constructions besides SVC. For example, simply searching for Frage and stellen might incorrectly include:
- “eine Frage stellen” (an ordinary verbal nominal collocation)
- “es stellt sich die Frage” (a reflexive verb construction)
The main purposes of concordance reading are to determine the exact form of each SVC and to find the precise query syntax. To determine the exact form involves the following steps:
- Distinguishing SVCs (e.g., in Frage stellen) from ordinary verbal nominal collocations (e.g., Antrag stellen).
- Determining prepositions and articles:
- in (den)? Zusammenhang stellen
- ins Gespräch ziehen vs. in ein Gespräch ziehen
- Identifying inflectional variations (case, number, negation):
- in Zusammenhang (accusative) stellen vs. im Zusammenhang (dative) stehen
- in Gang kommen vs. in die Gänge kommen
A precise query must ensure that the verbal noun (e.g., Frage) appears in a prepositional phrase (in Frage) dependent on the support verb (stellen)
Conclusion
Finally, I propose a workflow that combines association measures and concordance reading for an exhaustive search for SVCs. As discussed above, using association measures improves efficiency with minimal impact on completeness. Although the SVCs in German generally have a uniform structure, because of the numerous nuances in different instances, manual concordance reading is necessary to insure the accuracy.
- Create a collocation list for each support verb
- Filter the list with Document Frequency
- Mark high-association verbal nouns as candidates
- Conduct concordance reading for candidate pairs
- Determine the exact SVC form and extract from the corpus
Ideas from the RC21 Project Symposium
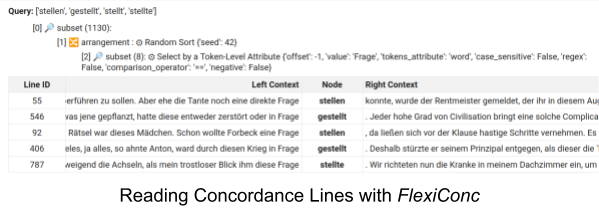
I would like to thank Nathan Dykes for providing me the opportunity to participate in the poster session of RC21 Project Symposium (19-21 March 2025). The event provided valuable feedback on my work and deepened my understanding of corpus linguistics methodologies. Thanks to its node-based structure, FlexiConc revealed usefulness in determining the exact form of SVCs, while KorAP (IDS Mannheim) may offer better rule-based solutions to the dependency problem. I also plan to explore Laurence Anthony’s AI-enhanced concordance tool to assess automation possibilities in dataset collection.
References
- Allerton, D. J. Stretched Verb Constructions in English, London, New York: Routledge, 2002.
- Harm, Volker. Funktionsverbgefüge des Deutschen: Untersuchungen zu einer Kategorie zwischen Lexikon und Grammatik, Berlin, Boston: De Gruyter, 2021.
- Gries, Stefan. Frequency, Dispersion, Association and Keyness: Revising and tupleizing: corpus-linguistic measures, Amsterdam, Philadelphia: John Benjamins Publishing Company, 2024.
Online resources
- Anthony, Laurence, Common statistics used in corpus linguistics: September 27, 2023.
https://www.laurenceanthony.net/resources/statistics/common_statistics_used_in_corpus_linguistics.pdf - Quick Reference for the Simple Query Syntax.
https://cqpw-prod.vip.sydney.edu.au/CQPweb/doc/cqpweb-simple-syntax-help.pdf - Uszkoreit, Hans et al., Tiger Annotationsschema: July 2003.
https://www.ims.uni-stuttgart.de/documents/ressourcen/korpora/tiger-corpus/annotation/tiger_scheme-syntax.pdf - STTS-Tags gemäß Tiger-Annotationsschema.
https://www.linguistik.hu-berlin.de/de/institut/professuren/korpuslinguistik/mitarbeiter-innen/hagen/STTS_Tagset_Tiger